fastNLP.modules¶
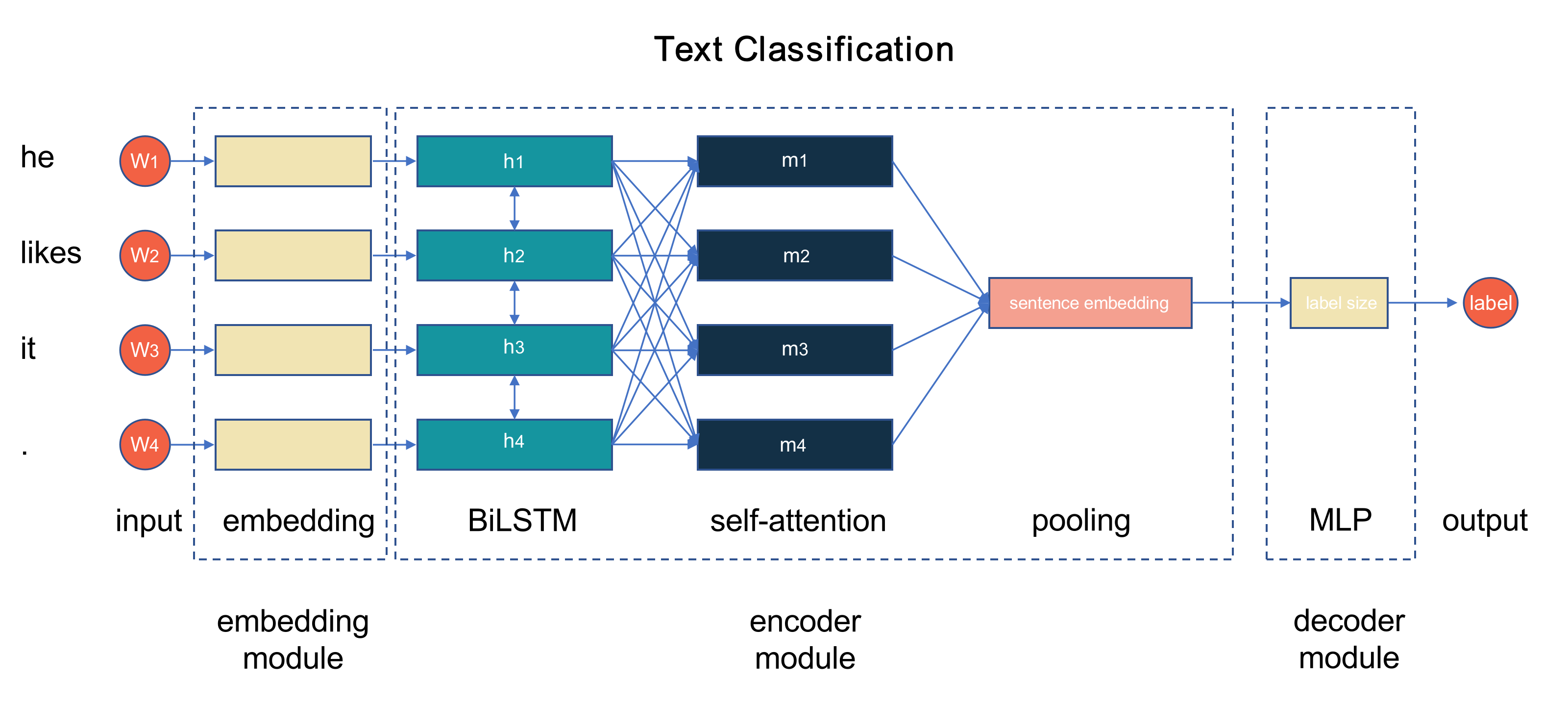
大部分用于的 NLP 任务神经网络都可以看做由 embedding 、 encoder 、
decoder 三种模块组成。 本模块中实现了 fastNLP 提供的诸多模块组件,
可以帮助用户快速搭建自己所需的网络。几种模块的功能和常见组件如下:
| 类型 | 功能 | 常见组件 |
|---|---|---|
| embedding | 参见 /fastNLP.embeddings |
Elmo, Bert |
| encoder | 将输入编码为具有表示能力的向量 | CNN, LSTM, Transformer |
| decoder | 将具有某种表示意义的向量解码为需要的输出形式 | MLP, CRF |
| 其它 | 配合其它组件使用的组件 | Dropout |
-
class
fastNLP.modules.ConvolutionCharEncoder(char_emb_size=50, feature_maps=(40, 30, 30), kernels=(1, 3, 5), initial_method=None)[源代码]¶ 别名
fastNLP.modules.ConvolutionCharEncoderfastNLP.modules.encoder.ConvolutionCharEncoderchar级别的卷积编码器.
-
__init__(char_emb_size=50, feature_maps=(40, 30, 30), kernels=(1, 3, 5), initial_method=None)[源代码]¶ 参数: - char_emb_size (int) -- char级别embedding的维度. Default: 50 :例: 有26个字符, 每一个的embedding是一个50维的向量, 所以输入的向量维度为50.
- feature_maps (tuple) -- 一个由int组成的tuple. tuple的长度是char级别卷积操作的数目, 第`i`个int表示第`i`个卷积操作的filter.
- kernels (tuple) -- 一个由int组成的tuple. tuple的长度是char级别卷积操作的数目, 第`i`个int表示第`i`个卷积操作的卷积核.
- initial_method -- 初始化参数的方式, 默认为`xavier normal`
-
-
class
fastNLP.modules.LSTMCharEncoder(char_emb_size=50, hidden_size=None, initial_method=None)[源代码]¶ 别名
fastNLP.modules.LSTMCharEncoderfastNLP.modules.encoder.LSTMCharEncoderchar级别基于LSTM的encoder.
-
class
fastNLP.modules.ConvMaxpool(in_channels, out_channels, kernel_sizes, activation='relu')[源代码]¶ 别名
fastNLP.modules.ConvMaxpoolfastNLP.modules.encoder.ConvMaxpool集合了Convolution和Max-Pooling于一体的层。给定一个batch_size x max_len x input_size的输入,返回batch_size x sum(output_channels) 大小的matrix。在内部,是先使用CNN给输入做卷积,然后经过activation激活层,在通过在长度(max_len) 这一维进行max_pooling。最后得到每个sample的一个向量表示。
-
__init__(in_channels, out_channels, kernel_sizes, activation='relu')[源代码]¶ 参数: - in_channels (int) -- 输入channel的大小,一般是embedding的维度; 或encoder的output维度
- out_channels (int,tuple(int)) -- 输出channel的数量。如果为list,则需要与kernel_sizes的数量保持一致
- kernel_sizes (int,tuple(int)) -- 输出channel的kernel大小。
- activation (str) -- Convolution后的结果将通过该activation后再经过max-pooling。支持relu, sigmoid, tanh
-
-
class
fastNLP.modules.LSTM(input_size, hidden_size=100, num_layers=1, dropout=0.0, batch_first=True, bidirectional=False, bias=True)[源代码]¶ 别名
fastNLP.modules.LSTMfastNLP.modules.encoder.LSTMLSTM 模块, 轻量封装的Pytorch LSTM. 在提供seq_len的情况下,将自动使用pack_padded_sequence; 同时默认将forget gate的bias初始化 为1; 且可以应对DataParallel中LSTM的使用问题。
-
__init__(input_size, hidden_size=100, num_layers=1, dropout=0.0, batch_first=True, bidirectional=False, bias=True)[源代码]¶ 参数: - input_size -- 输入 x 的特征维度
- hidden_size -- 隐状态 h 的特征维度. 如果bidirectional为True,则输出的维度会是hidde_size*2
- num_layers -- rnn的层数. Default: 1
- dropout -- 层间dropout概率. Default: 0
- bidirectional -- 若为
True, 使用双向的RNN. Default:False - batch_first -- 若为
True, 输入和输出Tensor形状为 :(batch, seq, feature). Default:False - bias -- 如果为
False, 模型将不会使用bias. Default:True
-
forward(x, seq_len=None, h0=None, c0=None)[源代码]¶ 参数: - x -- [batch, seq_len, input_size] 输入序列
- seq_len -- [batch, ] 序列长度, 若为
None, 所有输入看做一样长. Default:None - h0 -- [batch, hidden_size] 初始隐状态, 若为
None, 设为全0向量. Default:None - c0 -- [batch, hidden_size] 初始Cell状态, 若为
None, 设为全0向量. Default:None
Return (output, (ht, ct)): output: [batch, seq_len, hidden_size*num_direction] 输出序列 和 ht,ct: [num_layers*num_direction, batch, hidden_size] 最后时刻隐状态.
-
-
class
fastNLP.modules.StarTransformer(hidden_size, num_layers, num_head, head_dim, dropout=0.1, max_len=None)[源代码]¶ 别名
fastNLP.modules.StarTransformerfastNLP.modules.encoder.StarTransformerStar-Transformer 的encoder部分。 输入3d的文本输入, 返回相同长度的文本编码
paper: https://arxiv.org/abs/1902.09113
-
__init__(hidden_size, num_layers, num_head, head_dim, dropout=0.1, max_len=None)[源代码]¶ 参数: - hidden_size (int) -- 输入维度的大小。同时也是输出维度的大小。
- num_layers (int) -- star-transformer的层数
- num_head (int) -- head的数量。
- head_dim (int) -- 每个head的维度大小。
- dropout (float) -- dropout 概率. Default: 0.1
- max_len (int) -- int or None, 如果为int,输入序列的最大长度, 模型会为输入序列加上position embedding。 若为`None`,忽略加上position embedding的步骤. Default: None
-
-
class
fastNLP.modules.TransformerEncoder(num_layers, **kargs)[源代码]¶ 别名
fastNLP.modules.TransformerEncoderfastNLP.modules.encoder.TransformerEncodertransformer的encoder模块,不包含embedding层
-
class
fastNLP.modules.VarRNN(*args, **kwargs)[源代码]¶ 基类
fastNLP.modules.VarRNNBase别名
fastNLP.modules.VarRNNfastNLP.modules.encoder.VarRNNVariational Dropout RNN. 相关论文参考:A Theoretically Grounded Application of Dropout in Recurrent Neural Networks (Yarin Gal and Zoubin Ghahramani, 2016)-
__init__(*args, **kwargs)[源代码]¶ 参数: - input_size -- 输入 x 的特征维度
- hidden_size -- 隐状态 h 的特征维度
- num_layers -- rnn的层数. Default: 1
- bias -- 如果为
False, 模型将不会使用bias. Default:True - batch_first -- 若为
True, 输入和输出Tensor形状为 (batch, seq, feature). Default:False - input_dropout -- 对输入的dropout概率. Default: 0
- hidden_dropout -- 对每个隐状态的dropout概率. Default: 0
- bidirectional -- 若为
True, 使用双向的RNN. Default:False
-
-
class
fastNLP.modules.VarLSTM(*args, **kwargs)[源代码]¶ 基类
fastNLP.modules.VarRNNBase别名
fastNLP.modules.VarLSTMfastNLP.modules.encoder.VarLSTMVariational Dropout LSTM. 相关论文参考:A Theoretically Grounded Application of Dropout in Recurrent Neural Networks (Yarin Gal and Zoubin Ghahramani, 2016)-
__init__(*args, **kwargs)[源代码]¶ 参数: - input_size -- 输入 x 的特征维度
- hidden_size -- 隐状态 h 的特征维度
- num_layers -- rnn的层数. Default: 1
- bias -- 如果为
False, 模型将不会使用bias. Default:True - batch_first -- 若为
True, 输入和输出Tensor形状为 (batch, seq, feature). Default:False - input_dropout -- 对输入的dropout概率. Default: 0
- hidden_dropout -- 对每个隐状态的dropout概率. Default: 0
- bidirectional -- 若为
True, 使用双向的LSTM. Default:False
-
-
class
fastNLP.modules.VarGRU(*args, **kwargs)[源代码]¶ 基类
fastNLP.modules.VarRNNBase别名
fastNLP.modules.VarGRUfastNLP.modules.encoder.VarGRUVariational Dropout GRU. 相关论文参考:A Theoretically Grounded Application of Dropout in Recurrent Neural Networks (Yarin Gal and Zoubin Ghahramani, 2016)-
__init__(*args, **kwargs)[源代码]¶ 参数: - input_size -- 输入 x 的特征维度
- hidden_size -- 隐状态 h 的特征维度
- num_layers -- rnn的层数. Default: 1
- bias -- 如果为
False, 模型将不会使用bias. Default:True - batch_first -- 若为
True, 输入和输出Tensor形状为 (batch, seq, feature). Default:False - input_dropout -- 对输入的dropout概率. Default: 0
- hidden_dropout -- 对每个隐状态的dropout概率. Default: 0
- bidirectional -- 若为
True, 使用双向的GRU. Default:False
-
-
class
fastNLP.modules.MaxPool(stride=None, padding=0, dilation=1, dimension=1, kernel_size=None, ceil_mode=False)[源代码]¶ 别名
fastNLP.modules.MaxPoolfastNLP.modules.encoder.MaxPoolMax-pooling模块。
-
class
fastNLP.modules.MaxPoolWithMask[源代码]¶ 别名
fastNLP.modules.MaxPoolWithMaskfastNLP.modules.encoder.MaxPoolWithMask带mask矩阵的max pooling。在做max-pooling的时候不会考虑mask值为0的位置。
-
class
fastNLP.modules.KMaxPool(k=1)[源代码]¶ 别名
fastNLP.modules.KMaxPoolfastNLP.modules.encoder.KMaxPoolK max-pooling module.
-
class
fastNLP.modules.AvgPool(stride=None, padding=0)[源代码]¶ 别名
fastNLP.modules.AvgPoolfastNLP.modules.encoder.AvgPool给定形如[batch_size, max_len, hidden_size]的输入,在最后一维进行avg pooling. 输出为[batch_size, hidden_size]
-
class
fastNLP.modules.AvgPoolWithMask[源代码]¶ 别名
fastNLP.modules.AvgPoolWithMaskfastNLP.modules.encoder.AvgPoolWithMask给定形如[batch_size, max_len, hidden_size]的输入,在最后一维进行avg pooling. 输出为[batch_size, hidden_size], pooling 的时候只会考虑mask为1的位置
-
class
fastNLP.modules.MultiHeadAttention(input_size, key_size, value_size, num_head, dropout=0.1)[源代码]¶ 别名
fastNLP.modules.MultiHeadAttentionfastNLP.modules.encoder.MultiHeadAttentionTransformer当中的MultiHeadAttention
-
class
fastNLP.modules.MLP(size_layer, activation='relu', output_activation=None, initial_method=None, dropout=0.0)[源代码]¶ 别名
fastNLP.modules.MLPfastNLP.modules.decoder.MLP多层感知器
注解
隐藏层的激活函数通过activation定义。一个str/function或者一个str/function的list可以被传入activation。 如果只传入了一个str/function,那么所有隐藏层的激活函数都由这个str/function定义; 如果传入了一个str/function的list,那么每一个隐藏层的激活函数由这个list中对应的元素定义,其中list的长度为隐藏层数。 输出层的激活函数由output_activation定义,默认值为None,此时输出层没有激活函数。
Examples:
>>> net1 = MLP([5, 10, 5]) >>> net2 = MLP([5, 10, 5], 'tanh') >>> net3 = MLP([5, 6, 7, 8, 5], 'tanh') >>> net4 = MLP([5, 6, 7, 8, 5], 'relu', output_activation='tanh') >>> net5 = MLP([5, 6, 7, 8, 5], ['tanh', 'relu', 'tanh'], 'tanh') >>> for net in [net1, net2, net3, net4, net5]: >>> x = torch.randn(5, 5) >>> y = net(x) >>> print(x) >>> print(y)
-
__init__(size_layer, activation='relu', output_activation=None, initial_method=None, dropout=0.0)[源代码]¶ 参数: - size_layer (List[int]) -- 一个int的列表,用来定义MLP的层数,列表中的数字为每一层是hidden数目。MLP的层数为 len(size_layer) - 1
- activation (Union[str,func,List[str]]) -- 一个字符串或者函数的列表,用来定义每一个隐层的激活函数,字符串包括relu,tanh和 sigmoid,默认值为relu
- output_activation (Union[str,func]) -- 字符串或者函数,用来定义输出层的激活函数,默认值为None,表示输出层没有激活函数
- initial_method (str) -- 参数初始化方式
- dropout (float) -- dropout概率,默认值为0
-
-
class
fastNLP.modules.ConditionalRandomField(num_tags, include_start_end_trans=False, allowed_transitions=None, initial_method=None)[源代码]¶ 别名
fastNLP.modules.ConditionalRandomFieldfastNLP.modules.decoder.ConditionalRandomField条件随机场。提供forward()以及viterbi_decode()两个方法,分别用于训练与inference。
-
__init__(num_tags, include_start_end_trans=False, allowed_transitions=None, initial_method=None)[源代码]¶ 参数: - num_tags (int) -- 标签的数量
- include_start_end_trans (bool) -- 是否考虑各个tag作为开始以及结尾的分数。
- to_tag_id(int)]] allowed_transitions (List[Tuple[from_tag_id(int),) -- 内部的Tuple[from_tag_id(int), to_tag_id(int)]视为允许发生的跃迁,其他没有包含的跃迁认为是禁止跃迁,可以通过 allowed_transitions()函数得到;如果为None,则所有跃迁均为合法
- initial_method (str) -- 初始化方法。见initial_parameter
-
forward(feats, tags, mask)[源代码]¶ 用于计算CRF的前向loss,返回值为一个batch_size的FloatTensor,可能需要mean()求得loss。
参数: - feats (torch.FloatTensor) -- batch_size x max_len x num_tags,特征矩阵。
- tags (torch.LongTensor) -- batch_size x max_len,标签矩阵。
- mask (torch.ByteTensor) -- batch_size x max_len,为0的位置认为是padding。
返回: torch.FloatTensor, (batch_size,)
-
viterbi_decode(logits, mask, unpad=False)[源代码]¶ 给定一个特征矩阵以及转移分数矩阵,计算出最佳的路径以及对应的分数
参数: - logits (torch.FloatTensor) -- batch_size x max_len x num_tags,特征矩阵。
- mask (torch.ByteTensor) -- batch_size x max_len, 为0的位置认为是pad;如果为None,则认为没有padding。
- unpad (bool) -- 是否将结果删去padding。False, 返回的是batch_size x max_len的tensor; True,返回的是 List[List[int]], 内部的List[int]为每个sequence的label,已经除去pad部分,即每个List[int]的长度是这 个sample的有效长度。
返回: 返回 (paths, scores)。 paths: 是解码后的路径, 其值参照unpad参数. scores: torch.FloatTensor, size为(batch_size,), 对应每个最优路径的分数。
-
-
fastNLP.modules.viterbi_decode(logits, transitions, mask=None, unpad=False)[源代码]¶ 别名
fastNLP.modules.viterbi_decodefastNLP.modules.decoder.viterbi_decode给定一个特征矩阵以及转移分数矩阵,计算出最佳的路径以及对应的分数
参数: - logits (torch.FloatTensor) -- batch_size x max_len x num_tags,特征矩阵。
- transitions (torch.FloatTensor) -- n_tags x n_tags,[i, j]位置的值认为是从tag i到tag j的转换; 或者(n_tags+2) x (n_tags+2), 其中n_tag是start的index, n_tags+1是end的index;
- mask (torch.ByteTensor) -- batch_size x max_len, 为0的位置认为是pad;如果为None,则认为没有padding。
- unpad (bool) -- 是否将结果删去padding。False, 返回的是batch_size x max_len的tensor; True,返回的是 List[List[int]], 内部的List[int]为每个sequence的label,已经除去pad部分,即每个List[int]的长度是这 个sample的有效长度。
返回: 返回 (paths, scores)。 paths: 是解码后的路径, 其值参照unpad参数. scores: torch.FloatTensor, size为(batch_size,), 对应每个最优路径的分数。
-
fastNLP.modules.allowed_transitions(tag_vocab: Union[fastNLP.core.vocabulary.Vocabulary, dict], encoding_type=None, include_start_end=False)[源代码]¶ 别名
fastNLP.modules.allowed_transitionsfastNLP.modules.decoder.allowed_transitions给定一个id到label的映射表,返回所有可以跳转的(from_tag_id, to_tag_id)列表。
参数: - tag_vocab (Vocabulary,dict) -- 支持类型为tag或tag-label。只有tag的,比如"B", "M"; 也可以是"B-NN", "M-NN", tag和label之间一定要用"-"隔开。如果传入dict,格式需要形如{0:"O", 1:"B-tag1"},即index在前,tag在后。
- encoding_type (str) -- 支持"bio", "bmes", "bmeso", "bioes"。默认为None,通过vocab自动推断
- include_start_end (bool) -- 是否包含开始与结尾的转换。比如在bio中,b/o可以在开头,但是i不能在开头; 为True,返回的结果中会包含(start_idx, b_idx), (start_idx, o_idx), 但是不包含(start_idx, i_idx); start_idx=len(id2label), end_idx=len(id2label)+1。为False, 返回的结果中不含与开始结尾相关的内容
返回: List[Tuple(int, int)]], 内部的Tuple是可以进行跳转的(from_tag_id, to_tag_id)。